前情提要:我的说法比较白话,希望可以更好理解其中一些观念,这篇会以中文为主,专有名词还是用英文,好吧应该会中英穿插,自己学的时候感觉听中文会吸收比较快,也可能是我英文比较烂的关系 ̄□ ̄||欢迎点赞收藏评论给建议,感谢~
-
2024/04/17周三,已更新
问1: 为什么要学计算机架构Computer Architecture(CA)?
答:
In broadest definition,CA是allow us using manufacturing technologies来efficiently execution information processing application的abstraction/implementation layer;CA主要指ISA和microarchitecture;本质上是software和hardware的contract契约及interface,包括software怎么看到hardware,hardware有哪些部分是software visible的,它们有哪些互动interaction等。

问2: Architecture/ISA vs Microarchitecture/Organization?
答:
1. 观念: 清楚什么是ISA定义的,什么是Microarchitecture定义的即可。
2. ISA定义的: input/output;data types/sizes;operations(instructions and how they work);execution semantics(interrupt);programmer visible state(memory and register)。
3. Microarchitecture定义的: implement ISA for some metrics(speed,energy,cost)的tradeoffs;e.g., pipline number and pipline depth,cache size,silicon area,bus widths,ALU widths,exe ordering,peak power。
4. Microarchitecture像是implement ISA的choice,ISA一样的computer可以有很多不一样的microarchitecture,取决于computer要用在embeding space还是high performance space。
问3: pipline哪一个cycle哪一条instruction在什么stage一定要清楚?
例题: 来自《Computer Architecture a Quantitative Approach》第六版,Page C-71,Problem C.1 a,b,c,d,e,f,g

a. Data hazards are caused by data dependences in the code. Whether a dependency causes a hazard depends on the machine implementation (i.e., number of pipeline stages). List all of the data dependences in the code above. Record the register, source instruction, and destination instruction; for example, there is a data dependency for register x1 from the ld to the addi.
b. Show the timing of this instruction sequence for the 5-stage RISC pipeline without any forwarding or bypassing hardware but assuming that a register read and a write in the same clock cycle “forwards” through the register file, as between the add and or shown in Figure C.5. Use a pipeline timing chart like that in Figure C.8. Assume that the branch is handled by flushing the pipeline. If all memory references take 1 cycle, how many cycles does this loop take to execute?
c. Show the timing of this instruction sequence for the 5-stage RISC pipeline with full forwarding and bypassing hardware. Use a pipeline timing chart like that shown in Figure C.8. Assume that the branch is handled by predicting it as not taken. If all memory references take 1 cycle, how many cycles does this loop take to execute?
d. Show the timing of this instruction sequence for the 5-stage RISC pipeline with full forwarding and bypassing hardware, as shown in Figure C.6. Use a pipeline timing chart like that shown in Figure C.8. Assume that the branch is handled by predicting it as taken. If all memory references take 1 cycle, how many cycles does this loop take to execute?
e. High-performance processors have very deep pipelines—more than 15 stages. Imagine that you have a 10-stage pipeline in which every stage of the 5-stage pipeline has been split in two. The only catch is that, for data forwarding, data are forwarded from the end of a pair of stages to the beginning of the two stages where they are needed. For example, data are forwarded from the output of the second execute stage to the input of the first execute stage, still causing a 1-cycle delay. Show the timing of this instruction sequence for the 10-stage RISC pipeline with full forwarding and bypassing hardware. Use a pipeline timing chart like that shown in Figure C.8 (but with stages labeled IF1, IF2, ID1, etc.). Assume that the branch is handled by predicting it as taken. If all memory references take 1 cycle, how many cycles does this loop take to execute?
f. Assume that in the 5-stage pipeline, the longest stage requires 0.8 ns, and the pipeline register delay is 0.1 ns. What is the clock cycle time of the 5-stage pipeline? If the 10-stage pipeline splits all stages in half, what is the cycle time of the 10-stage machine?
g. Using your answers from parts (d) and (e), determine the cycles per instruction (CPI) for the loop on a 5-stage pipeline and a 10-stage pipeline. Make sure you count only from when the first instruction reaches the write-back stage to the end. Do not count the start-up of the first instruction. Using the clock cycle time calculated in part (f), calculate the average instruction execute time for each machine.
答:
a.

b.
Forwarding is performed only via the register file. Branch outcomes and targets are not known until the end of the execute stage. All instructions introduced to the pipeline prior to this point are flushed.
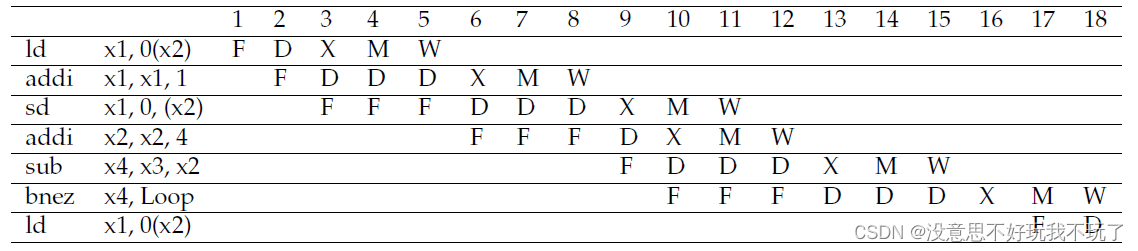
Since the initial value of x3 is x2+396 and equal instances of the loop add 4 to x2, the total number of iterations is 99. It takes 16 cycles between loop instances. The last loop takes two addition cycles since this latency cannot be overlapped with additional loop instances. The total number of cycles is 16×98+18 =1584.
c.

Assumes branch resolved in decode stage and no delay slots. Branch outcomes and targets are known now at the end of decode. Resolving branch in decode requires zero detect after bypass. The total number of cycles is 8×98+11=795.
d.
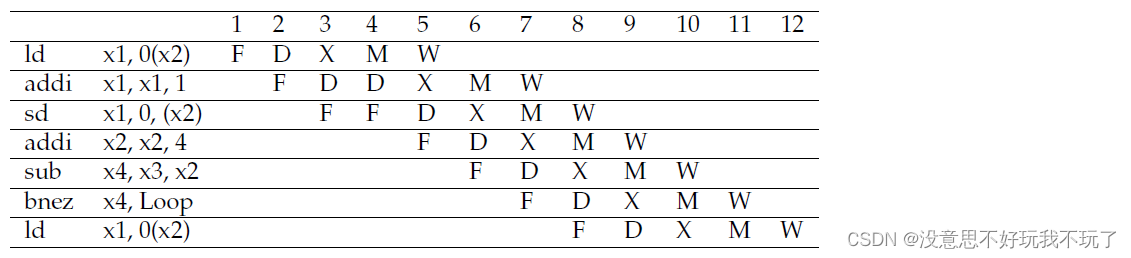
Assumes branch resolved in decode stage and no delay slots, and early pre-decode to determine and fetch target of branch in fetch stage. The total number of cycles is 7×98+11=697.
e.

The total number of cycles is 12×98+21=1197.
f.
5-stage: 0.8+0.1=0.9(ns); 10-stage: 0.8/2+0.1=0.5(ns)
g.
5-stage:
The 5th cycle to the 11th cycle took a total of 7 cycles and involved the execution of 6 instructions.
CPI = 7(cycles) / 6 (instructions) = 1.16
Average Instruction Execution Time = 1.16×0.9=1.044
10-stage:
The 10th cycle to the 21st cycle took a total of 12 cycles and involved the execution of 6 instructions.
CPI = 12(cycles) / 6 (instructions) = 2
Average Instruction Execution Time = 2×0.5=1
-
2024/00/00周x,未更新